
Kemajuan dalam bidang teknologi informasi telah memberikan dampak yang besar terhadap sektor perdagangan, yang mendorong perusahaan untuk merumuskan strategi yang cerdas agar tetap bersaing. Toko Jaya Plastik, yang merupakan toko ritel yang fokus pada produk plastik dan bahan makanan, sedang menghadapi tantangan seperti hadirnya kompetitor baru dan penurunan penjualan bulanan antara 10-15% pada pertengahan tahun 2023. Penurunan ini terjadi karena adanya pesaing yang dekat lokasinya, termasuk minimarket yang menawarkan beragam produk dan metode promosi yang menarik. Ketergantungan toko pada pandangan pemilik untuk melakukan analisis pasar serta kurangnya inovasi dalam pendekatan penjualannya semakin memperburuk kondisi ini.
Untuk menangani masalah itu, Toko Jaya Plastik harus merancang strategi untuk meningkatkan pendapatan dan meminimalkan kerugian. Salah satu metode yang efisien adalah menganalisis keranjang belanja dengan teknik data mining. Dengan memeriksa informasi transaksi, toko dapat mengenali pola belanja konsumen dan mengambil keputusan bisnis yang lebih baik. Algoritma Apriori dan FP-Growth dipilih karena kemudahan implementasinya dan efisiensinya. Secara umum, dalam data mining, terdapat dua jenis metode, yaitu metode prediktif dan deskriptif. Metode prediktif melibatkan penggunaan beberapa variabel untuk memprediksi nilai atau jenis variabel lain yang tidak diketahui, dengan tujuan menemukan pola tertentu. Contoh teknik yang termasuk dalam metode prediktif antara lain klasifikasi, regresi, dan deteksi anomali.
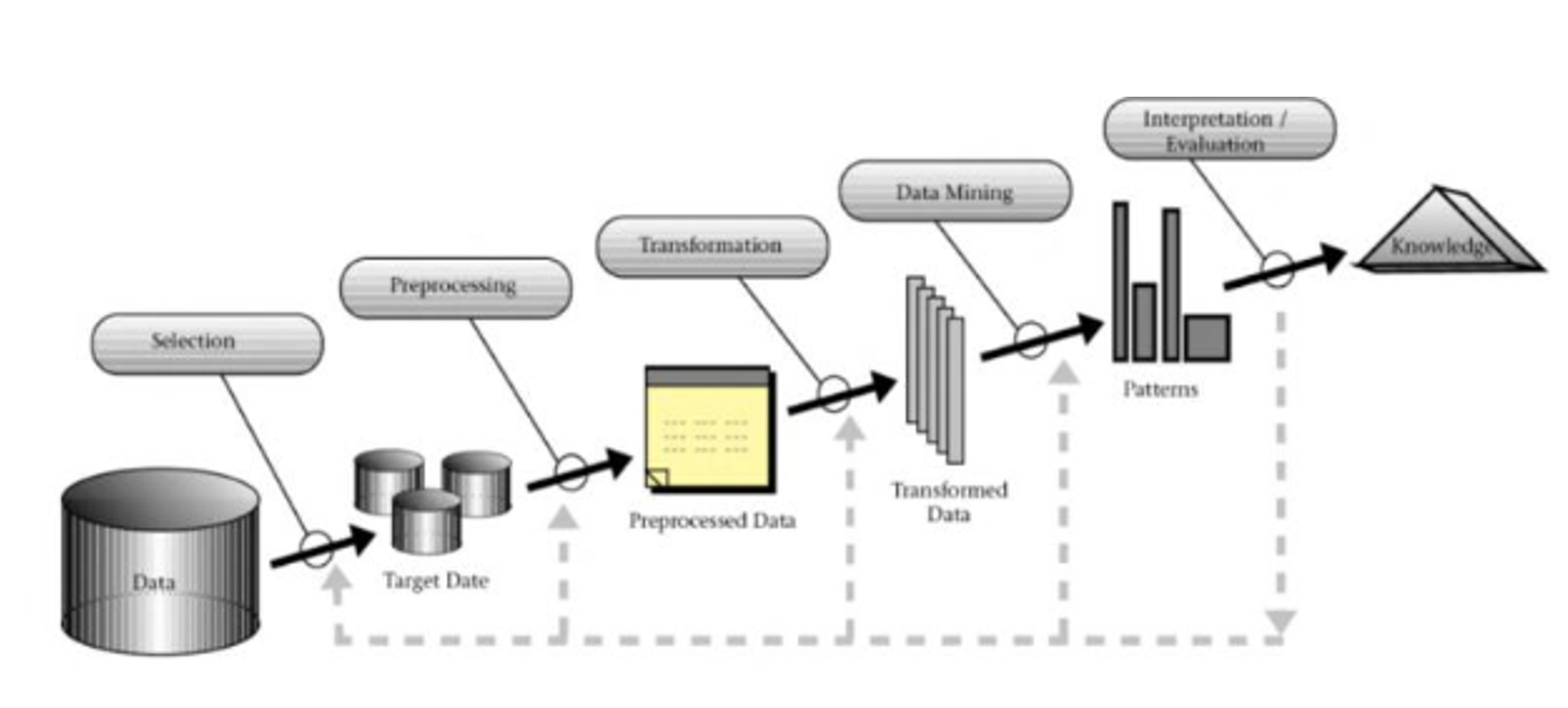
Gambar 1. Knowledge Discovery
Tahapan proses pada data mining yang dipresentasikan pada gambar 1 adalah sebagai berikut : Selection, tahap di mana data dipilih sebelum diproses pada tahap preprocessing data dan kemudian disimpan dalam berkas terpisah untuk dilakukan proses data mining; Preprocessing, tahapan untuk mengolah data sehingga siap digunakan dengan memeriksa dan memperbaiki kesalahan yang ada; Transformasi, di mana data yang telah dipilih mengalami transformasi sehingga sesuai untuk diproses dalam data mining; Data mining, proses penggalian pola dari data menggunakan berbagai teknik dan metode; dan interpretation/evaluation, yang melibatkan pengujian dan pemeriksaan untuk memverifikasi kesesuaian pola yang ditemukan dengan fakta atau hipotesis yang telah ada sebelumnya.
Market basket analysis adalah teknik dalam data mining yang bertujuan menemukan hubungan antara atribut yang sering muncul bersama dalam transaksi. Apriori adalah metode yang ditemukan oleh Rakesh Agrawal dan Ramakrishnan Srikant pada tahun 1994, menggunakan konsep frequent itemsets untuk mengidentifikasi aturan asosiasi. Algoritma ini menerapkan pendekatan level-wise, di mana himpunan k-item digunakan untuk menemukan himpunan (k+1)-item. Proses dimulai dengan menemukan himpunan 1-itemsets (L1) yang sering muncul, lalu digunakan sebagai basis untuk menemukan L2, L3, dan seterusnya, hingga tidak ada lagi k-itemsets yang sering muncul. Setiap kali Lk ditemukan, diperlukan pemindaian lengkap dari database. Untuk meningkatkan efisiensi, Apriori menggunakan sifat penting yang dikenal sebagai Apriori property. Prinsipnya adalah jika suatu itemset I tidak memenuhi ambang support minimum (min_sup), maka semua supersetnya juga tidak frequent. Oleh karena itu, ruang pencarian dapat dikurangi dengan mengabaikan itemsets yang tidak memenuhi min_sup. Algoritma Apriori terdiri dari dua fase proses: menemukan semua frequent itemsets dan menghasilkan aturan asosiasi dari itemsets tersebut.
1. Join step, pada tahap ini, dilakukan pembangkitan candidate generation yang disimbolkan dengan (Ck). Sebuah himpunan calon k-itemset dibuat dengan menggabungkan Lk-1 dengan dirinya sendiri.
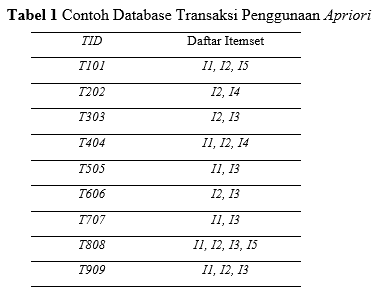
2. Prune step, Ck adalah himpunan yang berisi himpunan-himpunan yang lebih besar dari Lk, di mana tidak semua himpunan tersebut frequent, tetapi semua k-itemset yang frequent dimasukkan ke dalam Ck. Pada langkah ini, database akan dipindai kembali untuk menghitung jumlah dukungan dari semua calon Ck. Setelah itu, calon yang memenuhi syarat dukungan minimum akan disebut sebagai Lk. Untuk mengurangi jumlah item di Ck, jika subset (k-1) dari k-itemset tidak termasuk dalam Lk-1, maka calon tersebut pasti tidak sering muncul dan bisa dihapus dari Ck. Untuk penjelasan lebih lanjut, contoh penggunaan algoritma Apriori berikut disediakan. Tabel 2.1 menunjukkan database yang terdiri dari kode transaksi dan daftar item yang dibeli dalam setiap transaksi. Database ini terdiri dari 9 transaksi, atau |D| = 9.
FP-Growth, singkatan dari frequent-pattern growth, adalah suatu pendekatan yang menghasilkan frequent itemset tanpa perlu membuat candidate generation secara lengkap. Langkah awalnya adalah mengubah database menjadi sebuah FP-tree, yang pada dasarnya adalah sebuah pohon yang memiliki sifat-sifat sebagai berikut.
1.Ada satu akar yang diberi label "null". Sejumlah item awal membentuk cabang-cabang dari akar tersebut dan merupakan tabel header item yang sering muncul.
2.Setiap node dalam subtree item awal memiliki tiga komponen: label item, jumlah, dan node-link. Label item yang terdaftar ditampilkan pada node item, jumlah dari transaksi menunjukkan total dari masing-masing elemen yang mencapai node ini, dan node-link menghubungkan node berikutnya pada FP-tree yang memiliki label item yang sama, ditunjukkan dengan panah putus-putus.
3.Setiap entri dalam frequent-item-header pada tabel terdiri dari dua komponen: nama item dan kepala dari node-link (suatu titik pada simpul awal FP-tree yang menyimpan nama item).
Dalam mengevaluasi hasil, kita menggunakan dua faktor pengukuran, yaitu generalitas (generality) dan reliabilitas (reliability) dari association rules yang dihasilkan (Gunadi & Sensuse, 2016). Ukuran generalitas memberikan informasi tentang seberapa sering setiap item muncul dalam aturan asosiasi dibandingkan dengan total transaksi keseluruhan.
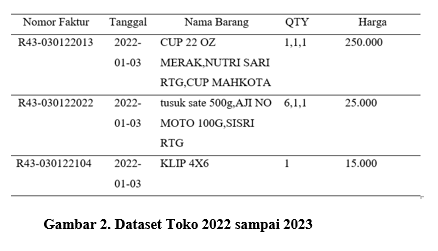
Pengumpulan dataset merupakan tahap pertama yang dilakukan pada penelitian ini dengan mengambil dataset yang ada pada Toko Jaya Plastik. Dataset yang dikumpulkan merupakan dataset pada tahun 2022 hingga tahun 2023 yang dipresentasikan pada gambar 2 berikut.
Setelah perhitungan itemset akan di dapatkan frequent itemset dari apriori dataset akan dibandingkan dengan kandidat support dengan minimum support dan sekaligus menghitung panjang dari kombinasi yang akan diimplementasikan dalam gambar 3 berikut.

Dari perhitungan algoritma Fp-Growth setelah pembentukan Fp-tree dan kemudian conditional pattern base lalu menampilkan hasil dari pembentukan frequent itemset, di mana setiap item akan dibentuk dengan nilai support yang sesuai. Selanjutnya akan dibentuk association rule yang di representasikan pada gambar 4 berikut.

Pada tahap ini, hasil dari proses perhitungan data mining dari kedua algoritma yang menghasilkan frequent itemset akan dilakukan evaluasi dan pengambilan keputusan. Evaluasi ini melibatkan frequent itemset dan rule yang dihasilkan, serta pemeriksaan nilai kepercayaan, lift, dan analisa hasilnya di presentasikan pada gambar 5 berikut.

Analisis hasil dari kedua algoritma dapat disimpulkan berdasarkan perhitungan evaluasi di dapatkan untuk algoritma Apriori sebesar 0.096, sementara untuk Fp-Growth sebesar 0.096. Presentasi akurasi algoritma Apriori terhadap Fp-Growth sebesar 100% dan untuk Persentase akurasi algoritma FP-Growth terhadap Apriori sebesar 100% sehingga dengan hasil ini, disimpulkan bahwa kedua algoritma sama-sama memberikan akurasi yang sangat baik. Setelah dilakukan perhitungan terhadap data kedua menggunakan minimum support 0.006 dan minimum confidence 0.1, dari algoritma Apriori dan algoritma FP-Growth, didapatkan nilai yang sama untuk Frequent itemset, yaitu sebanyak 196, dan nilai rule yang dibentuk sebanyak 122. Kemudian, algoritma FP-Growth lebih cepat dalam melakukan eksekusi serta menggunakan memori yang lebih rendah karena FP-Growth melakukan perhitungan dengan hanya dua kali pemindaian dataset untuk membangun FP-Tree, sedangkan Apriori memerlukan lebih banyak pemindaian.
Dari perhitungan analisis algoritma Apriori dan algoritma FP-Growth, didapatkan hasil persentase akurasi algoritma Apriori terhadap FP-Growth sebesar 100%, dan persentase akurasi algoritma FP-Growth terhadap Apriori juga sebesar 100%. Hasil ini menunjukkan bahwa kedua algoritma memberikan akurasi yang sangat baik. Ini berarti bahwa hasil yang diperoleh dari kedua algoritma tersebut saling mendukung dan valid, menunjukkan keandalan dalam menemukan pola yang signifikan dalam dataset yang sama. Kombinasi item-set yang bisa dibentuk menjadi paket penjualan atau bundling, seperti paket yang mencakup plastik PE 15 Tawon, Tepung Beras Rose Brand, Selai Glaze Coklat 250g, dan Keju Winchees 250g, atau paket yang terdiri dari bahan kue RW Pewarna, Kertas Nasi Bulat, dan Minyak Wijen 150ML. Selain itu, dalam penyusunan rak, disarankan untuk menempatkan Cup Victory 60ml dekat dengan Cup Puding 120ml, serta Dancow Vanila dekat dengan bahan kue Chery Tangkai Merah/Hijau @4, dan Delfi Top Chocolate.
1) Menjadi referensi dalam penerapan teknologi data mining khususnya dalam membangun Market Basket Analysis dengan algortima Apriori dan FP-Growth untuk mengatasi permasalahan dalam penjualan toko retail.
2) Menghasilkan aturan asosiasi yang membantu toko retail dalam membuat strategi bisnis dengan memahami preferensi konsumen lebih baik dan mengembangkan strategi yang tepat sasaran untuk meningkatkan penjualan dan mengurangi kerugian inventaris.